Machine Learning คืออะไร?
Machine Learning อยู่กับเรามานานแล้ว นานตั้งแต่เกิดสำหรับหลายๆคน เพราะมันเริ่มต้นตั้งแต่สมัยปี 1959 ไม่ใช่เรื่องใหม่เลย
หากใครเคยดู The Imitation game เป็นเรื่องราวการถอดรหัสลับของนาซี ในสงครามโลกที่พลิกให้ฝั่งพันธมิตรเป็นฝ่ายชนะ จะเห็นเครื่อง ENIGMA ที่สร้างโดย Alan Turing บิดาแห่ง Computer Science ในปัจจุบัน (แต่เนื้อเรื่องไม่ได้มาทาง machine learning เลยนะ ไปทางทฤษฏีเกม เสียมากกว่า)

เจ้าเครื่องนี้มันก็คำนวนมั่วๆไปเรื่อยๆตามกลไกที่ตั้งและการจูนค่าต่างๆด้วยการหมุน ก้อนกลมๆ ที่อยู่หน้าเครื่องมากมาย เพื่อหาความสัมพันธ์ของรหัสลับ ที่ได้จากคลื่น บ้างก็กล่าวว่านี่คือ super computer เครื่องแรก ที่ทำเรื่อง machine learning
มาตอบคำถามในตอนแรกกันดีกว่า ว่าเรื่องวิเศษๆเหล่านั้นได้ทำอย่างไร
คำตอบคือ “เขาใช้ Machine Learning”
Machine Learning คือ การทำให้ระบบคอมพิวเตอร์เรียนรู้ได้ด้วยตนเอง โดยใช้ ข้อมูล
ย้ำดังๆ ตรงคำว่า โดยใช้ “ข้อมูล”
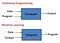
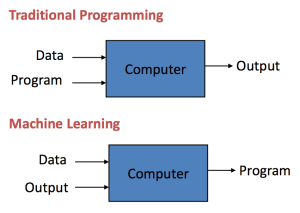
ซึ่งมันแตกต่างกับการเขียนโปรแกรมทั่วไป เพราะ Programming เราจะใส่ ข้อมูล (Data) และ Program เข้าไปเพื่อให้ได้ Output
แต่ Machine Learning เราไม่ได้ Program คำตอบ เราใส่ Data และ Output (ผลลัพธ์) เข้าไป เพื่อให้หา Program ที่จะนำไปตอบในอนาคตได้ว่า Input แบบนี้ Output จะเป็นอะไร
การใช้ข้อมูล ใช้ได้หลายแบบ ซึ่งมันจะแบ่งตามประเภทของ Machine Learning
Machine Learning มีอะไรบ้าง มีกี่แบบ
ศาสตร์แขนงนี้ กว้างเป็นทะเลครับ ถ้าจะให้แบ่ง ก็คงแบ่งได้ 3 แบบ
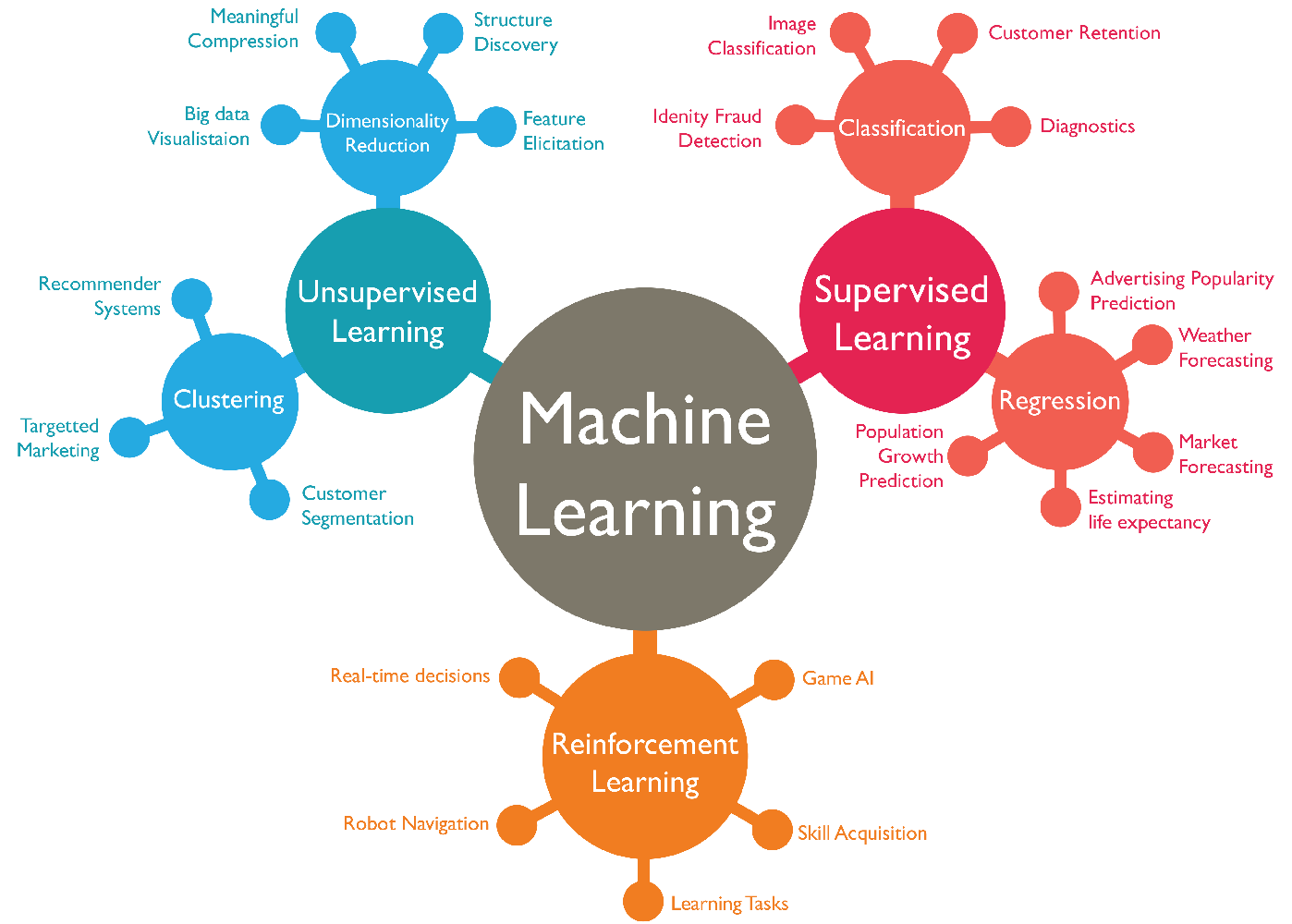
- Supervised Learning — เรียนรู้โดยมี data มาสอน
- Unsupervised Learning — เรียนรู้โดยไม่มี data สอน
- Reinforcement Learning — เรียนรู้ตามสภาพแวดล้อม
จะยกตัวอย่างชัดๆทีละเรื่อง เปรียบ Machine Learning สอนหุ่นยนต์ เหมือนการสอนเด็กน้อยให้แยกแก้วน้ำ ออกจาก ปากกา นะครับ
Supervised Learning
คือการเรียนรู้ โดยมี data มาสอน ชัดๆเลยก็คือ เด็กน้อยต้องไปสอบแยกแยะประเภทหมาแมว
เราจึงชี้ให้เด็กน้อย รู้จักแมว ชี้ให้รู้จักหมา หลายๆครั้งจนเด็กจได้
แล้วจึงอุ้มแมวมาถามเด็กว่า นี่อะไร?
เด็กน้อยก็จะตอบว่า “แมวค่ะ ❤ !!” (น่ารักเชียะ )
คอมพิวเตอร์ ก็ทำได้เช่นกัน แต่คอมพิวเตอร์ไม่มีตา !!
Data Scientist จึงต้องสร้าง Model ที่จะทำให้คอมพิวเตอร์รู้จักหมาแมวเข้าไป
โดยเอาข้อมูลหมาแมวใส่เข้าไปเช่น ใส่สี ใส่ลักษณะ ของแมวแต่ละตัวเข้าไป โดยแปลงให้เป็นภาษาคอมฯก่อน หรือเป็นตัวเลขนั่นเอง (เราเรียกมันว่า features)
พร้อมเฉลยไว้เลยว่า นี่คือแมว !! โดยใส่ข้อมูลเป็นตัวเลข (เราเรียกมันว่า labels)
และก็เอาหมาใส่เข้าไปพร้อมเฉลยว่านี่คือหมา
เมื่อใส่ Input เสร็จ Data Scientist ก็จะ Train Model เพื่อให้คอมพิวเตอร์แยกแยะหมาแมวได้ ตาม features
หลังจากนั้นเราก็เอา แมวมาให้ คอมพิวเตอร์ดู แล้วให้ตอบว่า นี่อะไร? คอมพิวเตอร์ก็ดูจาก features ที่ใส่ไปให้ และสามารถ Predict หรือตอบได้ว่า นี่คือแมว !!
Process การ Train และ Predict จะเป็นสิ่งที่ต้องทำเสมอในการทำ Machine Learning Model (ไว้มาลงลึกภาคปฏิบัติกัน)
(จริงๆการใส่ features ของภาพและวิธีการในการแยกแยะ ก็จะเป็นเรื่อง convolutional neural network แต่ตอนนี้ใจเย็นๆเอาแค่ Concept ก่อน)
ที่ใช้กันบ่อยโดยไม่รู้ตัวว่าเป็น Machine Learning คือการรัน Regression จ้า
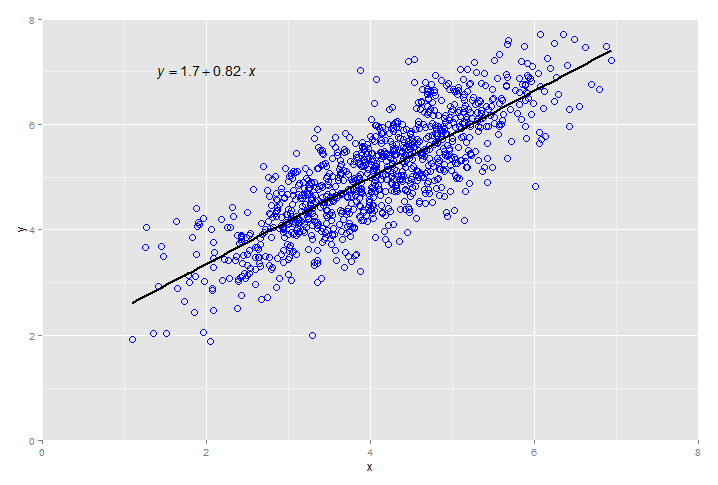
อื่นๆ ก็
- Support vector machine
- Naive Bayes
- Gradient boosting
- Classification trees / random forest
Unsupervised Learning
Unsupervised Learning นั้นตรงกันข้ามกับ Supervised Learning คือไม่มี Data มาสอน ถ้าให้เทียบก็คือ ไม่บอกเด็กน้อยแล้วว่า นี่คือหมาหรือแมว แต่ให้เด็กแยะแยะได้เอง (ซึ่งมันก็คงจะยากอะนะ)
แยกแยะเองได้อย่างไร?
เด็กน้อยก็จะสังเกตรูปร่างหน้าตาของแมวได้ รูปร่างหน้าตาของหมาได้ ว่ามันไม่เหมือนกัน แต่ในทางปฏิบัตินั้นยาก
สมมติว่าต้องมีแมว 3 สายพันธุ์ จะแยกง่ายสุดทำอย่างไร?
ก็แยกตามขนาด น้ำหนัก และส่วนสูง
บังเอิ๊นบังเอิญ ไปเจอรูปในเน็ตเป็น 3 สีพอดี เอามาติ๊ต่างเลยละกันว่า แกน y คือน้ำหนัก แกน x คือ ส่วนสูง อายุเท่าๆกันหมด
สายพันธ์เดียวกัน ที่อายุพอๆกัน ก็ควรจะเกาะกลุ่มกัน จริงมั้ยครับ ก็จะแบ่งได้ดังรูป
Model ที่จะหาตัวนี้ก็มีมากมาย ตัวอย่างโมเดลที่ง่ายที่สุด ก็จะเป็นการพยายามหาระยะห่างจากจุดๆหนึ่งไปอีกจุดหนึ่ง ก็จะได้การกระจุกตัวนั่นเอง
วิธีทำ ก็คล้ายๆเลย เอาข้อมูลใส่ไป ยำกัน ได้ออกมา จบบบ (ค่อยลงละเอียดเนอะ)
แต่ในชีวิตจริงมันซับซ้อนกว่านั้นมากครับ โมเดลที่ใช้ๆกันคือ
- K Nearest Neighbour
- K Mean
Reinforcement Learning
ในบรรดา Machine Learning ทั้งหมด Reinforcement Learning คือสิ่งที่ดูเป็น Artificial Intelligence (AI) ที่แท้ทรู ที่สุด เพราะจะเรียนรู้และเปลี่ยนไปตามสิ่งแวดล้อม
เข้าใจง่ายที่สุด ให้นึกถึงเวลา เด็ก ฝึกเดิน



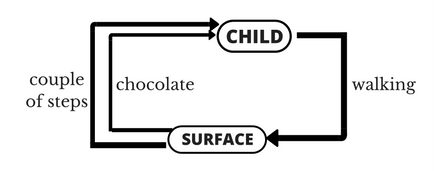
ในการเดินแต่ละครั้ง มีหลายปัจจัยที่ต้องคิด ที่เด็กน้อยจะต้องทำให้ได้คือ ยืนอย่างไร พื้นเสมอหรือไม่ ทิ้งน้ำหนักตัวตรงไหน กางแขนกี่องศา ก้าวเท้าระยะเท่าไหร่ ยกขาสูงแค่ไหน
มันดูยากมากสำหรับเด็กน้อย ก็ต้องทดลองเดิน ไปเรื่อยๆ
และให้รางวัลเด็กน้อยเป็นช็อคโกแลต เมื่อเด็กเดินสำเร็จ แต่ถ้าไม่เดินก็ไม่ให้รางวัลบ
เด็กน้อยก็จะเข้าใจว่า แบบนี้ดี แบบนี้ไม่ดี
อีกตัวอย่างหนึ่งที่ชัดคือการฝึกสัตว์เลี้ยงครับ
วิธีนี้เหมาะมากกับโจทย์บางประเภท คือการหากลยุทธ์ที่ทำให้ชนะเกม เช่นเดินออกจากเขาวงกต
ที่ใช้กันบ่อยๆคือ
- Markov Decision Processes (MDP)
- Q-learning
อิอิ
ตอบลบมันคือไรคับ
ตอบลบหาความรู้ครับอย่าทุจริตกันนะ
ตอบลบดีครับ
ตอบลบข้อ 6.1
ตอบลบK-Nearest Neighbour Algorithm) เป็นวิธีที่ใช้ในการจัดแบ่งคลาส โดยเทคนิคนี้จะตัดสินใจว่า คลาสใดที่จะแทนเงื่อนไขหรือกรณีใหม่ๆ ได้บ้าง โดยการตรวจสอบจำนวนบางจำนวน ในขั้นตอนวิธีการเพื่อนบ้านใกล้ที่สุด ของกรณีหรือเงื่อนไขที่เหมือนกันหรือใกล้เคียงกันมากที่สุด โดยจะหาผลรวม (Count Up) ของจำนวนเงื่อนไข หรือกรณีต่างๆ สำหรับแต่ละคลาส และกำหนดเงื่อนไขใหม่ๆ ให้คลาสที่เหมือนกันกับคลาสที่ใกล้เคียงกันมากที่สุด
ข้อ 6.2
Artificial Neuron Network : ANN) เป็นศาสตร์แขนงหนึ่งของทางด้านปัญญาประดิษฐ์ (Artifitial Intelligence : AI) มีรูปแบบโครงสร้างและการทำงานของการประมวลผลเหมือนกับสมองของสิ่งมีชีวิตซึ่งมีปรับเปลี่ยนตัวเองต่อการตอบสนองของอินพุตตามกฎของการเรียนรู้ (learning rule) หลังจากที่โครงข่ายได้เรียนรู้สิ่งที่ต้องการแล้ว โครงข่ายนั้นจะสามารถทำงานที่กำหนดไว้ได้โครงข่ายประสาทเทียมได้ถูกพัฒนาคิดค้นจากการทำงานของสมองมนุษย์โดยสมองมนุษย์ประกอบไปด้วยหน่วยประมวลผลเรียกว่า นิวรอน ( เซลล์ประสาท หรือ neuron) จำนวนนิวรอลในสมองมนุษย์มีอยู่ประมาณและมีการเชื่อมต่อกันอย่างมากมาย สมองมนุษย์จึงสามารถกล่าวได้ว่าเป็นคอมพิวเตอร์ที่มีการปรับตัวเอง (adaptive) ไม่เป็นเชิงเส้น (nonlinear) และทำงานแบบขนาน (parallel) ในการดูแลจัดการการทำงานร่วมกันของนิวรอนในสมอง การคำนวณเชิงนิวรอลเป็นการคำนวณที่เลียนแบบมาจากการทำงานของสมองมนุษย์นั่นเอง
ข้อ 6.3
Decision Tree เป็น model แบบ rule-based คือ สร้างกฎ if-else จากค่าของแต่ละ feature โดยไม่มีสมการมากำกับความสัมพันธ์ระหว่าง feature & target สิ่งที่สำคัญในการสร้าง Decision Tree คือ การเลือก split ค่า feature แต่ละครั้ง จะต้อง minimise ค่าของ cost functionให้น้อยที่สุด (regression — mse, classification- impurity, entropy)
ข้อ 6.4
Random Forest คือ model ที่ นำ Decision Tree หลายๆ tree มา Train ร่วมกัน (ตั้งแต่ 10 ต้น ถึง มากกว่า 1000 ต้น) โดยที่แต่ละ tree จะได้รับ feature และ data เป็น subset ของ feature และ data ทั้งหมด แบบ random ตอนทำ prediction ก็ให้แต่ละ Decision Tree ทำ prediction ของใครของมัน และเลือกผล final prediction จากค่า prediction ที่ได้รับการโหวตมากที่สุด! — technique ดังกล่าวเรียกว่า bagging หรือ boostrapping
ข้อ 6.5
Support Vector Machine: SVM) เป็นตัวจำแนกเชิงเส้น (Linear Classifier) แบบ 2 คลาส ซึ่งเป็นที่ยอมรับถึงประสิทธิภาพของการจำแนกที่เหนือว่าวิธีการจำแนกอื่นๆ ข้อได้เปรียบของ SVM คือมีประสิทธิภาพในการจำแนกข้อมูลที่มีมิติจำนวนมากได้ นอกจากนี้การใช้ฟังก์ชันเคอร์เนล (Kernel Function) เพื่อแปลงข้อมูลไปยังมิติที่สูงขึ้นในปริภูมิคุณลักษณะ (Feature Space) สามารถจำแนกข้อมูลที่มีความคลุมเครือได้อย่างมีประสิทธิภาพ หลักการของ SVM คือการหาเส้นตรงที่มีมาร์จินที่โตที่สุด (Maximum Margin) ที่สามารถแบ่งข้อมูลออกเป็น 2 คลาส ดังตัวอย่างในภาพที่ 2 เป็นข้อมูลขนาด 2 มิติ โดนถูกจำแนกออกเป็น 2 คลาส ได้แก่ + (Ο) และคลาส – (Δ) โดยเส้นตรงที่ใช้แบ่งข้อมูลมีมาร์จินเท่ากับ M=2w ซึ่ง เป็นความกว้างระหว่างเส้นตรงกับซัพพอร์เวคเตอร์ (Support vector) ของข้อมูลทั้ง 2 คลา
ใครอยู่มั้ย ตอบหน่อย ไมมันเงียบจัง
ตอบลบใครนิ
ลบเม่นๆ เห็นเงียบกันนึกว่าผิดลิ้งค์
ลบหาเจอละสัส5555
ตอบลบhttps://stackpython.medium.com/machine-learning-ep-2-cross-validation-70cbefb2dda4
ตอบลบข้อ5
ตอบลบข้อ4มีในไฟล์จาร
ตอบลบสไลด์ไหนอ่ะ หามะเจอ
ลบclass 7 เลื่อนดู
ลบมันมีแต่รูปง่ะ TT
ลบhttps://th.linkedin.com/pulse/%E0%B8%81%E0%B8%B2%E0%B8%A3%E0%B9%81%E0%B8%9A%E0%B8%87%E0%B8%82%E0%B8%AD%E0%B8%A1%E0%B8%A5%E0%B9%80%E0%B8%9E%E0%B8%AD%E0%B8%99%E0%B8%B3%E0%B8%A1%E0%B8%B2%E0%B8%97%E0%B8%94%E0%B8%AA%E0%B8%AD%E0%B8%9A%E0%B8%9B%E0%B8%A3%E0%B8%B0%E0%B8%AA%E0%B8%97%E0%B8%98%E0%B8%A0%E0%B8%B2%E0%B8%9E%E0%B8%82%E0%B8%AD%E0%B8%87%E0%B9%82%E0%B8%A1%E0%B9%80%E0%B8%94%E0%B8%A5-eakasit-pacharawongsakda
ตอบลบอันนี้คือ?
ลบข้อ 5 cross validation
ลบ#Show WCSS graph
ตอบลบplt.plot(range(1,7), wcss, linestyle='--', marker='o', label='WCSS value')
plt.title('WCSS value- Elbow method')
plt.xlabel('no of clusters- K value')
plt.ylabel('Wcss value')
plt.legend()
plt.show()
wไม่ใช่
ลบข้อไหนนิ
ลบpart C
ลบแปปๆ
ลบข้อ 7 อธิบายยังไงวะ
ตอบลบแบบเพราะจะแสดงกราฟอย่างงี้หรอ
ลบข้อ 1
ตอบลบhttps://medium.com/datacubator/validation-set-%E0%B8%AA%E0%B8%B3%E0%B8%84%E0%B8%B1%E0%B8%8D%E0%B9%84%E0%B8%89%E0%B8%99-1abf22a68b75
https://new.abb.com/news/detail/58004/deep-learning
ตอบลบ-ข้อ 4
ลบข้อ7,8 ยังไงวะ
ตอบลบถ้าอันไหนต้องส่งรูปอ่ะ เราส่งกันใน ig ดีไหม
ตอบลบ10.2 ตอบไรอ่ะ
ตอบลบจะร้องไห้ ข้อ 7 ขึ้นไปมะได้เลย ได้แค่ 9 TT
ตอบลบอยากได้ part c
ตอบลบimport pandas as pd
ตอบลบimport matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn import metrics
import numpy as np
from math import log
from sklearn.cluster import KMeans
#load data
data = pd.read_csv("https://gist.githubusercontent.com/seankross/a412dfbd88b3db70b74b/raw/5f23f993cd87c283ce766e7ac6b329ee7cc2e1d1/mtcars.csv")
X=data[['mpg','wt']]
y= data.iloc[:,0]
wcss=[]
for i in range(1,10):
kmeans= KMeans(n_clusters=i, init='k-means++', random_state=1)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
#print("WCSS values:")
#print(wcss)
plt.plot(range(1,10), wcss, linestyle='--', marker='o', label='WCSS value')
plt.title('WCSS value- Elbow method')
plt.xlabel('no of clusters- K value')
plt.ylabel('Wcss value')
plt.legend()
plt.show()
kmeans= KMeans(n_clusters=3, random_state=1)
kmeans.fit(X)
data['cluster']=kmeans.predict(X)
plt.scatter(data.loc[data['cluster']==0]['mpg'], data.loc[data['cluster']==0]['wt'], c='green',marker='*', label='cluster1-0')
plt.scatter(data.loc[data['cluster']==1]['mpg'], data.loc[data['cluster']==1]['wt'], c='red',marker='x', label='cluster2-1')
plt.scatter(data.loc[data['cluster']==2]['mpg'], data.loc[data['cluster']==2]['wt'], c='blue',marker='+', label='cluster3-2')
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], s=50, c='black', label='center')
plt.xlabel('mpg')
plt.ylabel('wt')
plt.legend()
plt.show()
ความคิดเห็นนี้ถูกผู้เขียนลบ
ตอบลบrange(1,11) นะ!!!!!
ตอบลบแล้วโค้ดที่ทำให้เปน 3 ครัสเตอร์นี่อันไหน
ลบตัด y= data.iloc[:,0] ออก
ตอบลบข้อ 10.2 ละ คชตอบไร
ตอบลบkmeans.inertia_
ลบ
ตอบลบอิอิ15 ธันวาคม 2564 00:26
#Show WCSS graph
plt.plot(range(1,7), wcss, linestyle='--', marker='o', label='WCSS value')
plt.title('WCSS value- Elbow method')
plt.xlabel('no of clusters- K value')
plt.ylabel('Wcss value')
plt.legend()
plt.show()
อันนี้คือข้อไหนอ่ะ
ลบ